Antenna
An antenna is a device to transmit and/or receive electromagnetic waves.
Electromagnetic waves are often referred to as radio waves. Most antennas are
resonant devices, which operate efficiently over a relatively narrow frequency
band. An antenna must be tuned (matched) to the same frequency band as the radio
system to which it is connected otherwise reception and/or transmission will be
impaired.
Types of antenna
There are 3 types of antennas used with mobile wireless, omnidirectional,
dish and panel antennas.
+ Omnidirectional radiate equally in all
directions
+ Dishes are very directional
+ Panels are not as directional
as Dishes.
Decibels
Decibels (dB) are the accepted method of describing a gain or loss
relationship in a communication system. If a level is stated in decibels, then
it is comparing a current signal level to a previous level or preset standard
level. The beauty of dB is they may be added and subtracted. A decibel
relationship (for power) is calculated using the following formula:
“A” might be the power applied to the connector on an antenna, the input
terminal of an amplifier or one end of a transmission line. “B” might be the
power arriving at the opposite end of the transmission line, the amplifier
output or the peak power in the main lobe of radiated energy from an antenna. If
“A” is larger than “B”, the result will be a positive number or gain. If “A” is
smaller than “B”, the result will be a negative number or loss.
You will notice that the “B” is capitalized in dB. This is because it refers
to the last name of Alexander Graham Bell.
Note:
+ dBi is a measure of the increase in signal (gain) by your antenna compared
to the hypothetical isotropic antenna (which uniformly distributes energy in all
directions) -> It is a ratio. The greater the dBi value, the higher the gain
and the more acute the angle of coverage.
+ dBm is a measure of signal power. It is the the power ratio in decibel (dB)
of the measured power referenced to one milliwatt (mW). The “m” stands for
“milliwatt”.
Example:
At 1700 MHz, 1/4 of the power applied to one end of a coax cable arrives at
the other end. What is the cable loss in dB?
Solution:
=> Loss = 10 * (- 0.602) = – 6.02 dB
From the formula above we can calculate
at 3 dB the power is reduced
by half. Loss = 10 * log (1/2) = -3 dB; this is an important number to
remember.
Beamwidth
The angle, in degrees, between the two half-power points (-3 dB) of an
antenna beam, where more than 90% of the energy is radiated.
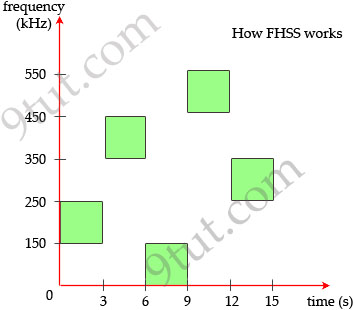
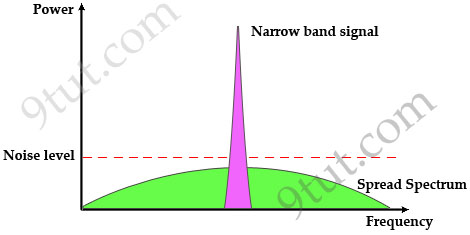
OFDM
OFDM was proposed in the late 1960s, and in 1970, US patent was issued. OFDM
encodes a single transmission into
multiple sub-carriers. All the slow
subchannel are then multiplexed into one fast combined channel.
The trouble with traditional FDM is that the guard bands waste bandwidth and
thus reduce capacity. OFDM selects channels that overlap but do not interfere
with each other.

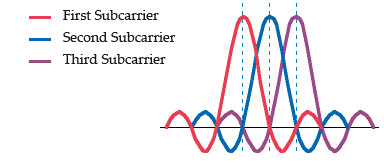
OFDM works because the frequencies of the subcarriers are selected so that at
each subcarrier frequency, all other subcarriers do not contribute to overall
waveform.
In this example, three subcarriers are overlapped but do not interfere with
each other. Notice that only the peaks of each subcarrier carry data. At the
peak of each of the subcarriers, the other two subcarriers have zero
amplitude.
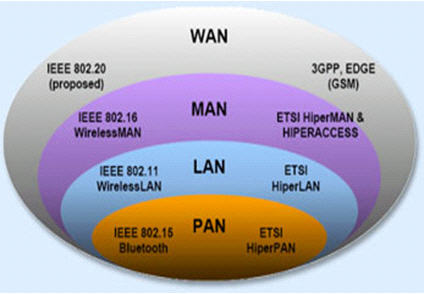
Types of network in CCNA Wireless
+ A
LAN (local area network) is a data communications
network that typically connects personal computers within a very limited
geographical (usually within a single building). LANs use a variety of wired and
wireless technologies, standards and protocols. School computer labs and home
networks are examples of LANs.
+ A
PAN (personal area network) is a term used to refer to
the interconnection of personal digital devices within a range of about 30 feet
(10 meters) and without the use of wires or cables. For example, a PAN could be
used to wirelessly transmit data from a notebook computer to a PDA or portable
printer.
+ A
MAN (metropolitan area network) is a public high-speed
network capable of voice and data transmission within a range of about 50 miles
(80 km). Examples of MANs that provide data transport services include local
ISPs, cable television companies, and local telephone companies.
+ A
WAN (wide area network) covers a large geographical area
and typically consists of several smaller networks, which might use different
computer platforms and network technologies. The Internet is the world’s largest
WAN. Networks for nationwide banks and superstore chains can be classified as
WANs.
Bluetooth
Bluetooth wireless technology is a short-range communications technology
intended to replace the cables connecting portable and/or fixed devices while
maintaining high levels of security. Connections between Bluetooth devices allow
these devices to communicate wirelessly through short-range, ad hoc networks.
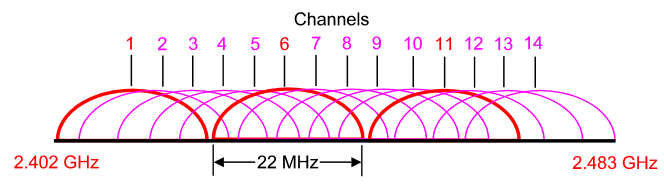
Bluetooth operates in the 2.4 GHz unlicensed ISM band.
Note:
Industrial, scientific and medical (ISM) band is a part of
the radio spectrum that can be used by anybody without a license in most
countries. In the U.S, the 902-928 MHz, 2.4 GHz and 5.7-5.8 GHz bands were
initially used for machines that emitted radio frequencies, such as RF welders,
industrial heaters and microwave ovens, but not for radio communications. In
1985, the FCC Rules opened up the ISM bands for wireless LANs and mobile
communications. Nowadays, numerous applications use this band, including
cordless phones, wireless garage door openers, wireless microphones, vehicle
tracking, amateur radio…
WiMAX
Worldwide Interoperability for Microwave Access (WiMax) is defined by the
WiMax forum and standardized by the IEEE 802.16 suite. The most current standard
is 802.16e.
Operates in two separate frequency bands, 2-11 GHz and 10-66 GHz
At the
higher frequencies, line of sight (LOS) is required – point-to-point links
only
In the lower region, the signals propagate without the requirement for
line of sight (NLOS) to customers
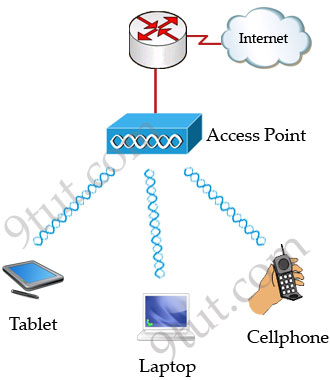
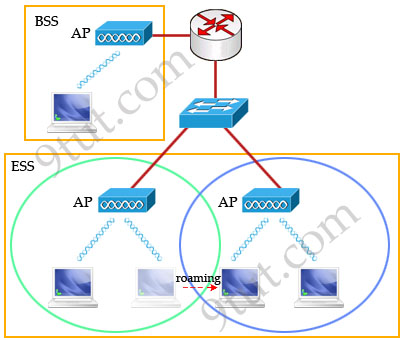
Basic Service Set (BSS)
A group of stations that share an access point are said to be part of one
BSS.
Extended Service Set (ESS)
Some WLANs are large enough to require multiple access points. A group of
access points connected to the same WLAN are known as an ESS. Within an ESS, a
client can associate with any one of many access points that use the same
Extended service set identifier (ESSID). That allows users to roam about an
office without losing wireless connection.
IEEE 802.11 standard
A family of standards that defines the physical layers (PHY) and the Media
Access Control (MAC) layer.
* IEEE 802.11a: 54 Mbps in the 5.7 GHz ISM band
* IEEE 802.11b: 11 Mbps in
the 2.4 GHz ISM band
* IEEE 802.11g: 54 Mbps in the 2.4 GHz ISM band
*
IEEE 802.11i: security. The IEEE initiated the 802.11i project to overcome the
problem of WEP (which has many flaws and it could be exploited easily)
* IEEE
802.11e: QoS
* IEEE 802.11f: Inter Access Point Protocol (IAPP)
More information about 802.11i:
The new security standard, 802.11i, which was ratified in June 2004, fixes
all WEP weaknesses. It is divided into three main categories:
1.
Temporary Key Integrity Protocol (TKIP) is a short-term
solution that fixes all WEP weaknesses. TKIP can be used with old 802.11
equipment (after a driver/firmware upgrade) and provides integrity and
confidentiality.
2.
Counter Mode with CBC-MAC Protocol
(CCMP) [RFC2610] is a new protocol, designed from ground up. It uses
AES as its cryptographic algorithm, and, since this is more CPU intensive than
RC4 (used in WEP and TKIP), new 802.11 hardware may be required. Some drivers
can implement CCMP in software. CCMP provides integrity and
confidentiality.
3.
802.1X Port-Based Network Access
Control: Either when using TKIP or CCMP, 802.1X is used for
authentication.
Wireless Access Points
There are two categories of Wireless Access Points (WAPs):
* Autonomous
WAPs
* Lightweight WAPs (LWAPs)
Autonomous WAPs operate independently, and each contains its
own configuration file and security policy. Autonomous WAPs suffer from
scalability issues in enterprise environments, as a large number of independent
WAPs can quickly become difficult to manage.
Lightweight WAPs (LWAPs) are centrally controlled using one
or more Wireless LAN Controllers (WLCs), providing a more scalable solution than
Autonomous WAPs.
Encryption
Encryption is the process of changing data into a form that can be read only
by the intended receiver. To decipher the message, the receiver of the encrypted
data must have the proper decryption key (password).
TKIP
TKIP stands for Temporal Key Integrity Protocol. It is basically a patch for
the weakness found in WEP. The problem with the original WEP is that an
attacker could recover your key after observing a relatively small amount of
your traffic. TKIP addresses that problem by automatically negotiating a new
key every few minutes — effectively never giving an attacker enough data to
break a key. Both WEP and WPA-TKIP use the RC4 stream cipher.
TKIP Session Key
* Different for every pair
* Different for every station
* Generated
for each session
* Derived from a “seed” called the passphrase
AES
AES stands for Advanced Encryption Standard and is a totally separate cipher
system. It is a 128-bit, 192-bit, or 256-bit block cipher and is considered the
gold standard of encryption systems today. AES takes more computing power to
run so small devices like Nintendo DS don’t have it, but is the most secure
option you can pick for your wireless network.
EAP
Extensible Authentication Protocol (EAP) [RFC 3748] is just the transport
protocol optimized for authentication, not the authentication method itself:
” EAP is an authentication framework which supports multiple authentication
methods. EAP typically runs directly over data link layers such as
Point-to-Point Protocol (PPP) or IEEE 802, without requiring IP. EAP provides
its own support for duplicate elimination and retransmission, but is reliant on
lower layer ordering guarantees. Fragmentation is not supported within EAP
itself; however, individual EAP methods may support this.” — RFC 3748, page
3
Some of the most-used EAP authentication mechanism are listed below:
* EAP-MD5: MD5-Challenge requires username/password, and is
equivalent to the PPP CHAP protocol [RFC1994]. This method does not provide
dictionary attack resistance, mutual authentication, or key derivation, and has
therefore little use in a wireless authentication enviroment.
*
Lightweight EAP (LEAP): A username/password combination is sent to a
Authentication Server (RADIUS) for authentication. Leap is a proprietary
protocol developed by Cisco, and is not considered secure. Cisco is phasing out
LEAP in favor of PEAP.
* EAP-TLS: Creates a TLS session
within EAP, between the Supplicant and the Authentication Server. Both the
server and the client(s) need a valid (x509) certificate, and therefore a PKI.
This method provides authentication both ways.
* EAP-TTLS:
Sets up a encrypted TLS-tunnel for safe transport of authentication data. Within
the TLS tunnel, (any) other authentication methods may be used. Developed by
Funk Software and Meetinghouse, and is currently an IETF
draft.
*EAP-FAST: Provides a way to ensure the same level of
security as EAP-TLS, but without the need to manage certificates on the client
or server side. To achieve this, the same AAA server on which the authentication
will occur generates the client credential, called the Protected Access
Credential (PAC).
* Protected EAP (PEAP): Uses, as EAP-TTLS,
an encrypted TLS-tunnel. Supplicant certificates for both EAP-TTLS and EAP-PEAP
are optional, but server (AS) certificates are required. Developed by Microsoft,
Cisco, and RSA Security, and is currently an IETF draft.
*
EAP-MSCHAPv2: Requires username/password, and is basically an EAP
encapsulation of MS-CHAP-v2 [RFC2759]. Usually used inside of a PEAP-encrypted
tunnel. Developed by Microsoft, and is currently an IETF draft.
RADIUS
Remote Authentication Dial-In User Service (RADIUS) is defined in [RFC2865]
(with friends), and was primarily used by ISPs who authenticated username and
password before the user got authorized to use the ISP’s network.
802.1X does not specify what kind of back-end authentication server must be
present, but RADIUS is the “de-facto” back-end authentication server used in
802.1X.
Roaming
Roaming is the movement of a client from one AP to another while still
transmitting. Roaming can be done across different mobility groups, but must
remain inside the same mobility domain. There are 2 types of roaming:
A client roaming from AP1 to AP2. These two APs are in the same mobility
group and mobility domain
Roaming in the
same Mobility Group
A client roaming from AP1 to AP2. These two APs are
in different mobility groups but in the same mobility domain